7 Week 7
7.2 R Instructions
7.2.1 Introductory remarks on time-to-event analysis
In a typical study of a cancer drug, patients are entered on the study and then followed until death. When the data are analyzed, some patients will have died but others will still be alive. For instance, if John Doe entered the study on 4/1/2017 and died on 3/31/2019, we know that he survived exactly two years on the drug. However, if Jane Doe entered the study on 7/1/2018 and was still alive on 6/30/2019, when the study was closed for analysis, we know that she lived for more than one year, but not how much longer. We say that Jane Doe was “censored”.
When running statistical analyses, we cannot ignore the fact that Jane’s data point “1 year survival” is actually “>1 year survival”. This means that, for instance, we couldn’t calculate the mean of Jane and Joe’s survival and say that average survival was 1.5 years.
The approach used in time-to-event analysis is known as “cumulative probability”. One way to think about this is the fairy tale about the brave knight who has to complete a series of challenges set by the king in order to win the hand of the princess in marriage. Imagine that he has to climb the wall of death, cross the valley of mists and slay the dragon. We might estimate the probability that he will die on each task as, respectively, 20%, 10% and 30%. In other words, he has an 80% chance of climbing the wall of death, a 90% chance of getting across the valley of mists and a 70% chance of slaying the dragon. To calculate the probability that he lives to marry the princess, we multiply those probabilities together to get 80% × 90% × 70% = 50%.
Now let’s apply that to a cancer study. As a simple example, imagine that there are 10 patients and that one dies every month. After four months, four patients have died and so the probability of survival at four months is, obviously, 60%. But let’s think about that using the same methods as we did for the fairy tale. There were 10 patients at the start of the trial, and one died at the end of the first month. Hence the chance of surviving the first month is 90%. Nine patients were alive at the start of the second month and 8 survived till the end of the month, giving a probability of surviving the second month as 8 ÷ 9 = 88.89%. We can do similar calculations for month 3 (7 ÷ 8 = 87.50%) and month 4 (6 ÷ 7 = 85.71%). If we multiply those probabilities together, we get 90% × 88.89% × 87.50% × 85.71% = 60% survival probability, exactly what we would expect.
However, let’s imagine that the research assistant comes back to us, saying that there has been a miscommunication. The patient who was said to have died after two months actually went back to her home country and we don’t know anything more about her, so she didn’t die, she was censored. Let’s do the calculation again. The first month is unchanged: 9 out of 10 = 90% survival rate. Nine patients were alive at the start of the second month and all were alive at the end of the month, a 100% survival rate. At the start of the third month, we only have 8 patients (10 minus 1 who died and 1 who was censored), so the probability of surviving month 3 is 7 ÷ 8 = 87.5% and the probability of surviving month 4 is 6 ÷ 7 = 85.71%. Now when we multiply 90% × 100% × 87.50% × 85.71% we get 67.5%. Now let’s imagine that the woman is actually found to be still alive, 8 months in. We now calculate the 4 months probability as 90% for month 1, 100% for month 2 (there were no deaths), 8 ÷ 9 = 88.89% for month 3 and 7 ÷ 8 = 87.50% for months 4, a survival probability of 90% × 100% × 88.89% × 87.50% = 70%.
Here are some key takeaways.
- Time-to-event analysis is all about probabilities. Note that 3 patients died in both the second and third example, but it would be unsound to say “Of the ten patients that entered the trial, 3 (30%) died”. You would need to say instead, “Three patients died. The probability of survival at four months was 67.5% / 70%” for example 2 / 3.
- Survival probabilities don’t change until there is a death. In example 2, for instance, there is a 100% chance of surviving the second month, so the survival probabilities at month 1 and 2 are the same. This is why survival curves look like “steps”, with the curve being flat (for periods when there are no deaths) and then a step down (when a death occurs).
- We don’t always have death as an endpoint. It could be cancer progression, change in treatment or in fact anything that takes place over time (in engineering studies, for instance, we look at time to failure of a machine part). So the usual terminology is to talk about “time to event” and the number of “events” rather than “survival” analysis.
7.2.2 Time to event data
You need at least two variables to describe a time to event dataset: how long the patients were followed (the time variable), and whether they had the event (e.g. were alive or dead) at last observation (the failure variable). The failure variable is coded 1 if the patient had the event (e.g. died, had a recurrence) and 0 otherwise. You can have any other variables (patient codes, stage of cancer, treatment, hair color, etc.) but these are not essential.
For survival analyses, you need to indicate that your outcome is a time-to-event outcome by providing both the event status, such as death, and time to event, for example time from surgery to death or last followup. The function used to do this is the Surv function from the {survival} package. The function is of the form Surv(t, d) where “t” is the time variable and “d” is the “failure” variable (e.g. died if 1, alive at last follow-up if 0).
The survfit function (also from the {survival} package) describes the survival data. It is common to report the median survival.
# Calculate descriptive statistics on time to event data
# The "~ 1" indicates that we want survival estimates for the entire group
survfit(Surv(t, d) ~ 1, data = example7a)## Call: survfit(formula = Surv(t, d) ~ 1, data = example7a)
##
## n events median 0.95LCL 0.95UCL
## [1,] 23 18 27 18 45You often also report the median time of follow-up for survivors, which can easily be calculated manually.
# Calculate median followup for survivors only
example7a %>%
filter(d == 0) %>% # Keep only the surviving patients
skim(t) # Remember, "p50" indicates the median| Name | Piped data |
| Number of rows | 5 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| t | 0 | 1 | 52.6 | 61.89 | 13 | 16 | 28 | 45 | 161 | ▇▂▁▁▂ |
You can also plot the survival curve by adding the plot function around your survfit function:
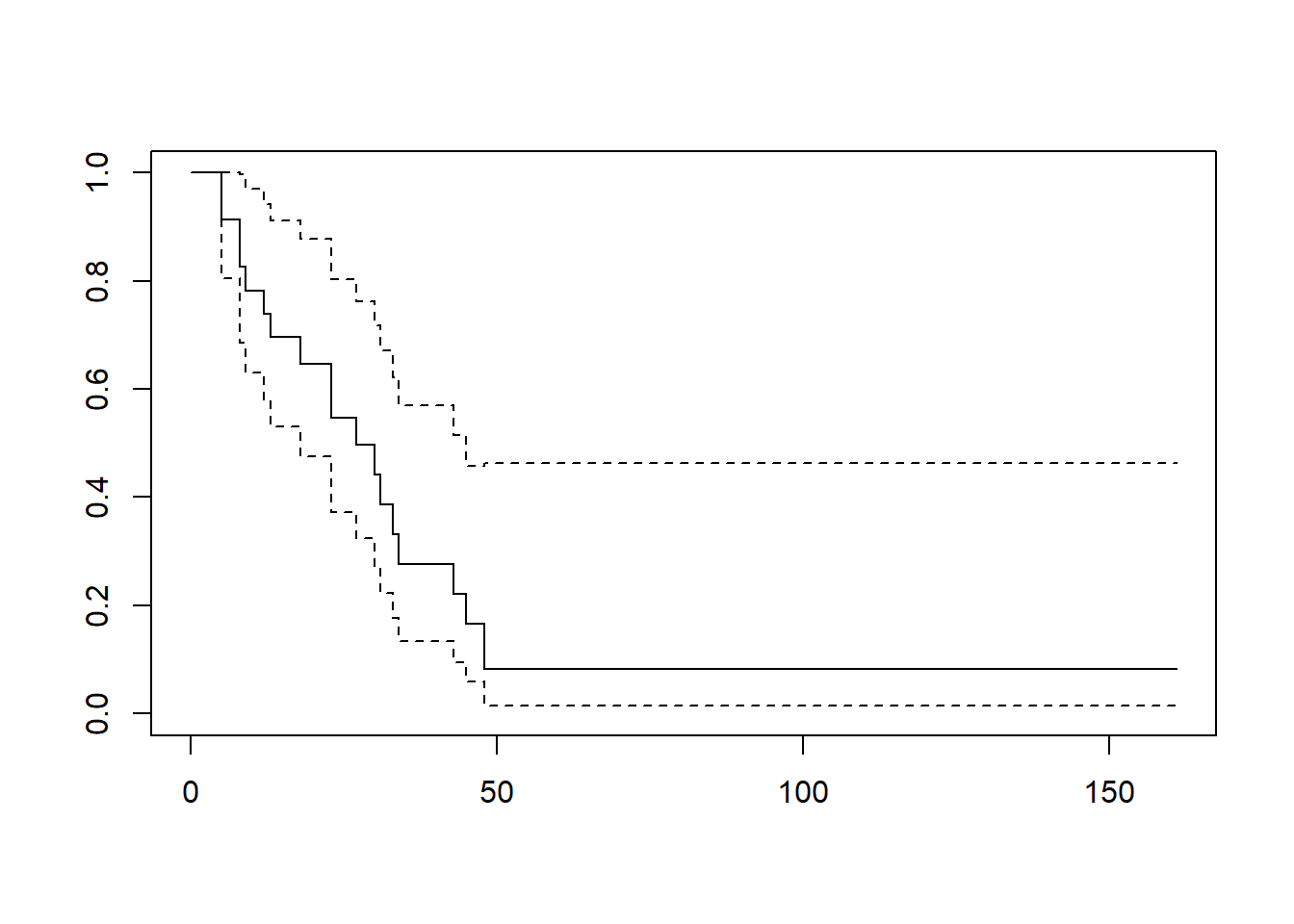
Use “~ covariate” instead of “~ 1” to plot survival curves by group:
# Plot survival curve by group (drug vs no drug)
# "~ drug" indicates to plot by "drug", vs "~ 1" which plots for all patients
plot(survfit(Surv(t, d) ~ drug, data = example7a))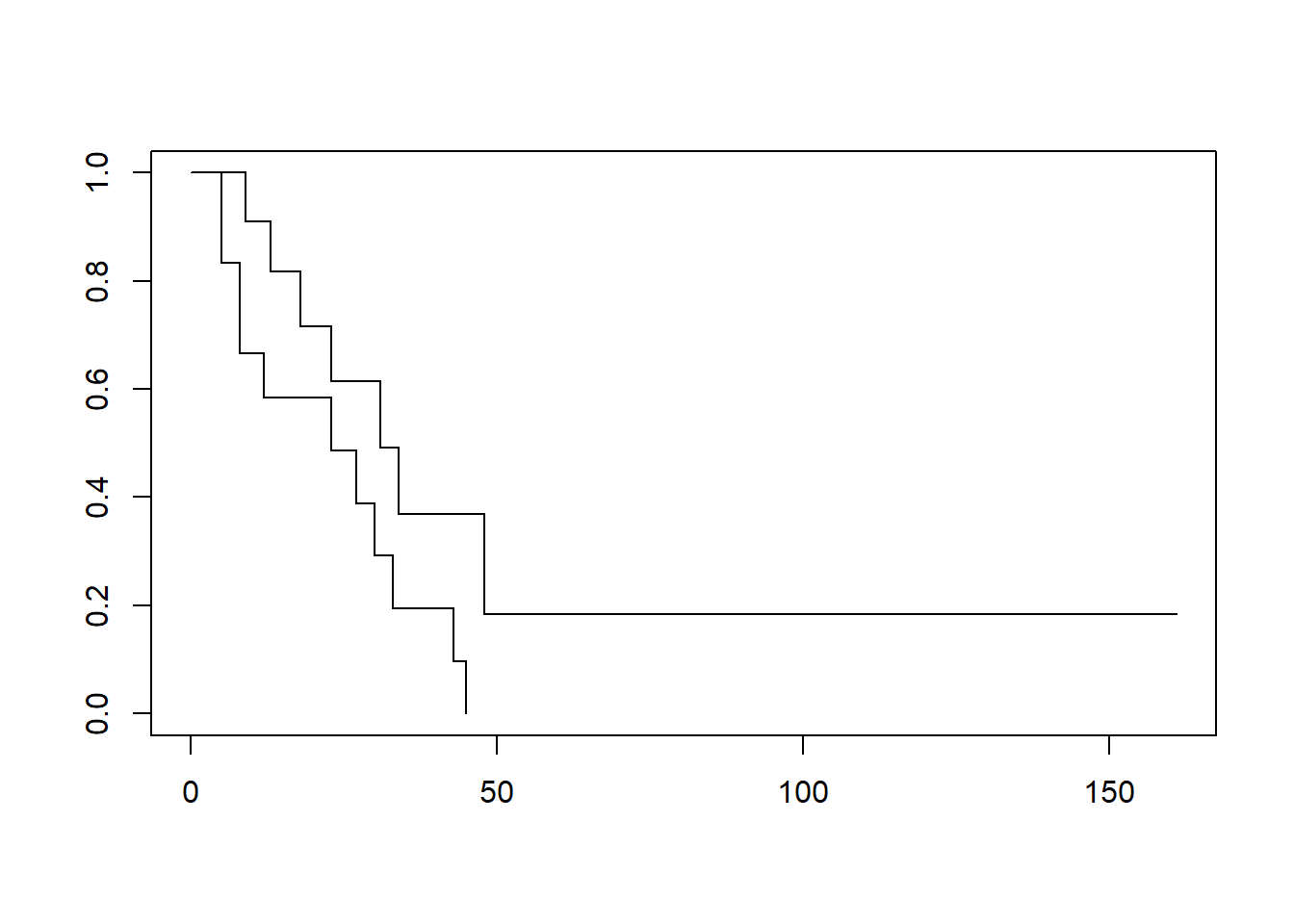
As you may notice, this graph shows both lines in black, which makes it difficult to determine which line corresponds to which group. However, you can add color to the lines to differentiate them. The order of the colors corresponds to the order of the variable values - in this case, drug is “0” and “1”, so the following code creates a graph where the placebo group (drug = 0) is plotted in blue and the drug group (drug = 1) is plotted in red.
# Plot survival curve by group (drug vs no drug) with colors
plot(survfit(Surv(t, d) ~ drug, data = example7a), col = c("blue", "red"))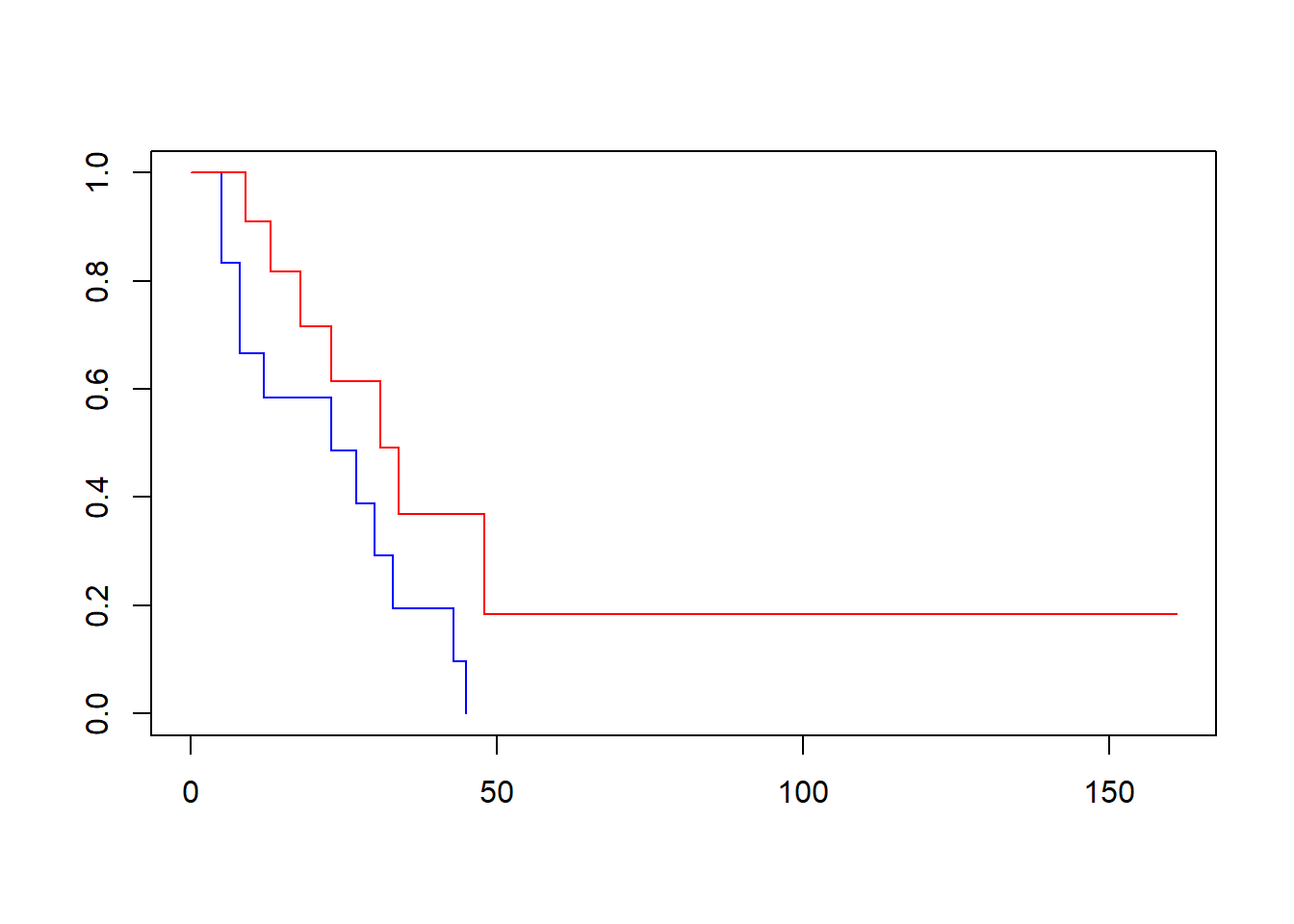
Graphs can be saved out by using the “Export” option at the top of the “Plots” tab.
The survdiff function compares survival for different groups. For example, the following code compares survival for each value of the variable “drug” (generally 0 and 1).
## Call:
## survdiff(formula = Surv(t, d) ~ drug, data = example7a)
##
## N Observed Expected (O-E)^2/E (O-E)^2/V
## drug=0 12 11 7.31 1.86 3.4
## drug=1 11 7 10.69 1.27 3.4
##
## Chisq= 3.4 on 1 degrees of freedom, p= 0.07Using the summary function with survfit lists all available followup times along with survival probabilities (you get a 95% C.I. as well):
## Call: survfit(formula = Surv(t, d) ~ 1, data = example7a)
##
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 5 23 2 0.9130 0.0588 0.8049 1.000
## 8 21 2 0.8261 0.0790 0.6848 0.996
## 9 19 1 0.7826 0.0860 0.6310 0.971
## 12 18 1 0.7391 0.0916 0.5798 0.942
## 13 17 1 0.6957 0.0959 0.5309 0.912
## 18 14 1 0.6460 0.1011 0.4753 0.878
## 23 13 2 0.5466 0.1073 0.3721 0.803
## 27 11 1 0.4969 0.1084 0.3240 0.762
## 30 9 1 0.4417 0.1095 0.2717 0.718
## 31 8 1 0.3865 0.1089 0.2225 0.671
## 33 7 1 0.3313 0.1064 0.1765 0.622
## 34 6 1 0.2761 0.1020 0.1338 0.569
## 43 5 1 0.2208 0.0954 0.0947 0.515
## 45 4 1 0.1656 0.0860 0.0598 0.458
## 48 2 1 0.0828 0.0727 0.0148 0.462# You can also summarize the survival by group:
summary(survfit(Surv(t, d) ~ drug, data = example7a))## Call: survfit(formula = Surv(t, d) ~ drug, data = example7a)
##
## drug=0
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 5 12 2 0.8333 0.1076 0.6470 1.000
## 8 10 2 0.6667 0.1361 0.4468 0.995
## 12 8 1 0.5833 0.1423 0.3616 0.941
## 23 6 1 0.4861 0.1481 0.2675 0.883
## 27 5 1 0.3889 0.1470 0.1854 0.816
## 30 4 1 0.2917 0.1387 0.1148 0.741
## 33 3 1 0.1944 0.1219 0.0569 0.664
## 43 2 1 0.0972 0.0919 0.0153 0.620
## 45 1 1 0.0000 NaN NA NA
##
## drug=1
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 9 11 1 0.909 0.0867 0.7541 1.000
## 13 10 1 0.818 0.1163 0.6192 1.000
## 18 8 1 0.716 0.1397 0.4884 1.000
## 23 7 1 0.614 0.1526 0.3769 0.999
## 31 5 1 0.491 0.1642 0.2549 0.946
## 34 4 1 0.368 0.1627 0.1549 0.875
## 48 2 1 0.184 0.1535 0.0359 0.944The times option allows you to get survival probabilities for specific timepoints. For example, at 1 year, 2 years and 5 years:
# Get survival probabilities for specific time points in full dataset
# "~ 1" indicates all patients
# "t" variable is in months, so 12, 24 and 60 months used for 1, 2 and 5 years
summary(survfit(Surv(t, d) ~ 1, data = example7a), times = c(12, 24, 60))## Call: survfit(formula = Surv(t, d) ~ 1, data = example7a)
##
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 12 18 6 0.7391 0.0916 0.5798 0.942
## 24 11 4 0.5466 0.1073 0.3721 0.803
## 60 1 8 0.0828 0.0727 0.0148 0.462If you’d like this information formatted in a table, you can use the function tbl_survfit from {gtsummary}. You can use the exact same code as above and simply substitute tbl_survfit for the summary function:
| Characteristic | Time 12 | Time 24 | Time 60 |
|---|---|---|---|
| Overall | 74% (58%, 94%) | 55% (37%, 80%) | 8.3% (1.5%, 46%) |
The coxph function (from {survival}) is for regression analyses. For example, a univariate regression for the effects of “drug” on survival:
## Call:
## coxph(formula = Surv(t, d) ~ drug, data = example7a)
##
## coef exp(coef) se(coef) z p
## drug -0.9155 0.4003 0.5119 -1.788 0.0737
##
## Likelihood ratio test=3.38 on 1 df, p=0.06581
## n= 23, number of events= 18# You can use the tbl_regression function with Cox models to see the hazard ratios
example7a_cox <- coxph(Surv(t, d) ~ drug, data = example7a)
tbl_regression(example7a_cox, exponentiate = TRUE)| Characteristic | HR | 95% CI | p-value |
|---|---|---|---|
| drug | 0.40 | 0.15, 1.09 | 0.074 |
| Abbreviations: CI = Confidence Interval, HR = Hazard Ratio | |||
The following multivariable model also includes some demographic and medical characteristics:
# Create multivariable Cox regression model
# You can use the pipe operator (%>%) to show the tbl_regression table directly
# without storing the Cox model
coxph(Surv(t, d) ~ drug + age + sex + marker, data = example7a) %>%
tbl_regression(exponentiate = TRUE)| Characteristic | HR | 95% CI | p-value |
|---|---|---|---|
| drug | 0.17 | 0.05, 0.65 | 0.010 |
| age | 1.01 | 0.97, 1.06 | 0.6 |
| sex | 2.76 | 0.88, 8.65 | 0.081 |
| marker | 0.45 | 0.19, 1.03 | 0.059 |
| Abbreviations: CI = Confidence Interval, HR = Hazard Ratio | |||
So, some typical code to analyze a dataset:
# Get median survival and number of events for group
# Use the "Surv" function to indicate the event status and time to event
survfit(Surv(t, d) ~ 1, data = example7a)## Call: survfit(formula = Surv(t, d) ~ 1, data = example7a)
##
## n events median 0.95LCL 0.95UCL
## [1,] 23 18 27 18 45| Name | Piped data |
| Number of rows | 5 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| t | 0 | 1 | 52.6 | 61.89 | 13 | 16 | 28 | 45 | 161 | ▇▂▁▁▂ |
# Look at predictors of survival
coxph(Surv(t, d) ~ drug + age + sex + marker, data = example7a) %>%
tbl_regression(exponentiate = TRUE)| Characteristic | HR | 95% CI | p-value |
|---|---|---|---|
| drug | 0.17 | 0.05, 0.65 | 0.010 |
| age | 1.01 | 0.97, 1.06 | 0.6 |
| sex | 2.76 | 0.88, 8.65 | 0.081 |
| marker | 0.45 | 0.19, 1.03 | 0.059 |
| Abbreviations: CI = Confidence Interval, HR = Hazard Ratio | |||
7.3 Assignments
# Copy and paste this code to load the data for week 7 assignments
lesson7a <- readRDS(here::here("Data", "Week 7", "lesson7a.rds"))
lesson7b <- readRDS(here::here("Data", "Week 7", "lesson7b.rds"))
lesson7c <- readRDS(here::here("Data", "Week 7", "lesson7c.rds"))
lesson7d <- readRDS(here::here("Data", "Week 7", "lesson7d.rds"))Try to do at least lesson7a and lesson7b.
lesson7a: This is a large set of data on patients receiving adjuvant therapy after surgery for colon cancer. Describe this dataset and determine which, if any, variables are prognostic in this patient group.
lesson7b: These are time to recurrence data on forty patients with biliary cancer treated at one of two hospitals, one of which treats a large number of cancer patients and one of which does not. Do patients treated at a “high volume” hospital have a longer time to recurrence?
lesson7c: These are data from a randomized trial comparing no treatment, levamisole (an immune stimulant) and levamisole combined with 5FU (a chemotherapy agent) and in the adjuvant treatment of colon cancer. Describe the dataset. What conclusions would you draw about the effectiveness of the different treatments?
lesson7d: More data on time to recurrence by hospital volume. Given this dataset, determine whether patients treated at a “high volume” hospital have a longer time to recurrence.